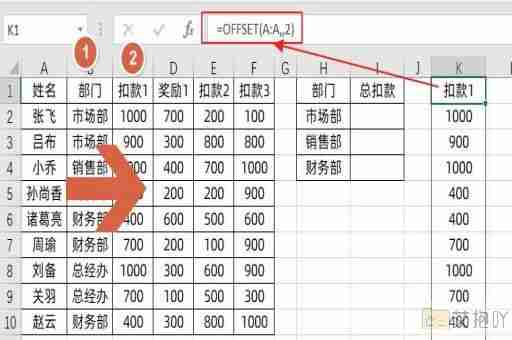
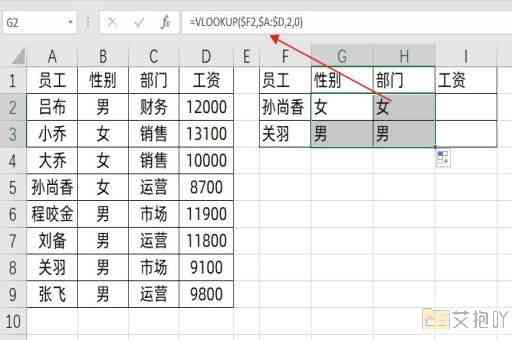
python3读取excel前10行数据
在python中,我们可以使用pandas库来读取excel文件。pandas是一个强大的数据处理库,它提供了一个简单易用的接口来处理各种格式的数据,包括csv、excel和sql数据库等。
我们需要安装pandas和openpyxl库。如果你还没有安装这两个库,可以使用以下命令进行安装:
```python
pip install pandas openpyxl
```
接下来,我们可以使用pandas的read_excel函数来读取excel文件。这个函数会返回一个dataframe对象,这是一个二维表格型的数据结构,非常适合用来处理表格型数据。
以下是一个简单的例子,演示了如何使用pandas读取excel文件的前10行数据:
```python
import pandas as pd
# 读取excel文件
df = pd.read_excel('file.xlsx')
# 获取前10行数据
head_df = df.head(10)
# 打印前10行数据
print(head_df)

```
在这个例子中,我们首先导入了pandas库,并使用read_excel函数读取了一个名为'file.xlsx'的excel文件。然后,我们使用head函数获取了这个dataframe的前10行数据,并将这些数据存储到了一个新的dataframe对象head_df中。我们打印出了这个新的dataframe。
需要注意的是,pandas的read_excel函数默认会读取excel文件的第一个工作表。如果你想要读取其他工作表,可以通过sheet_name参数指定。
pandas的read_excel函数还可以接受很多其他的参数,比如header(用于指定数据的列名)、usecols(用于指定要读取的列)和skiprows(用于指定要跳过的行)等。你可以根据自己的需求,灵活地使用这些参数。
pandas是一个非常强大且易用的数据处理库,它可以让我们轻松地处理各种格式的数据。如果你经常需要处理数据,那么学习pandas将会是非常有用的。

 上一篇
上一篇